What happened at CT days 2020?
Rasmus Dahlberg, 2020-09-14.
This year’s CT days were hosted remotely on September 8–9. The agenda covered a wide range of topics, such as making CT more newcomer friendly, updating user-agent policies, and what it takes to operate a log at scale. I do not intend to write about all of it, and especially not every little detail. You will be brought up to speed on some highlights and get further reading. All credit obviously goes to the people who presented sessions on this material.
New community website
You might be familiar with the current CT website. It is a little bit like an explosion of technical details and links from several years back that, if you digest it all, tell you how Google’s CT project works. This is not particularly welcoming for newcomers that need to grasp what CT is today and how it fits into the broader picture of the web’s public-key infrastructure. For example, CT is no longer Google’s own logging project, but rather an ecosystem of different people and organizations that come together with one mission: to detect maliciously or mistakenly issued certificates. This happens to be the first thing you will find when browsing the new community website. It is nifty looking, and I encourage you to browse it yourself. You will notice that the origin story of CT and its broader context is described, which helps the reader pick up the fundamentals from a combination of text and visualizations.
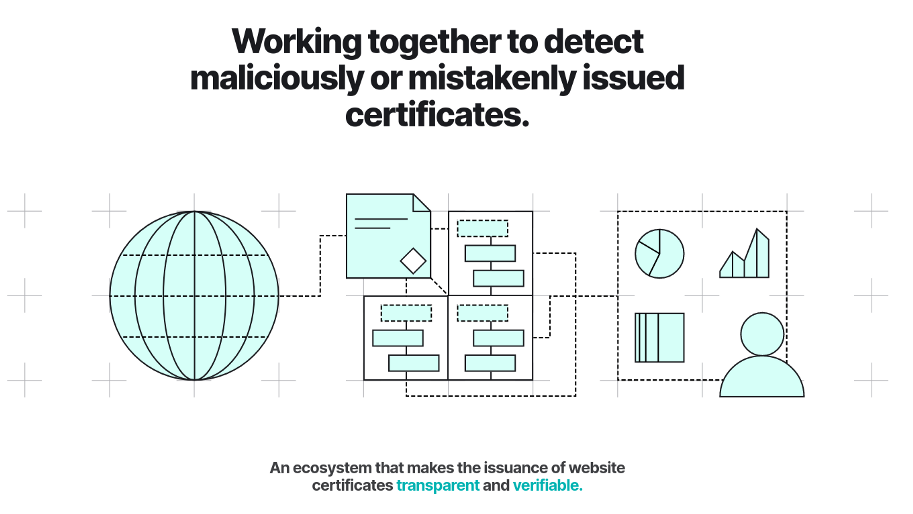 source: https://certificate.transparency.dev/
source: https://certificate.transparency.dev/
Ryan Hurst explained that we can think of the new community website as a place where newcomers can be directed to understand the value of CT and how it works. Moreover, it is our collective responsibility to add anything that is missing and keep it up-to-date. Anyone can submit pull requests on GitHub.
Policy updates
I can second that it is not always easy to understand every nuance of CT enforcement by different user agents. For example, I remember filing a bug not too long ago when noticing that Chromium (not to be confused with Google Chrome) disabled CT by default. In the future there might be a separate and lighter-weight Chromium CT policy that embedders could use as a starting point, but for now Google’s policy will be shaped solely for Chrome. This is reflected by the new CT policy website that is being drafted: the so-called Chrome Certificate Transparency Policy. Devon O’Brien appropriately described it as a complete overhaul of what the current policy states and how these requirements are framed specifically for enforcement in Chrome.
The CT community website will link the updated CT policy once it goes live in the near future. In the mean time, you can enjoy the draft and provide feedback to the Chrome CT team or the CT policy group. The recommended starting point is the different states that a CT log can be in. I am not going to detail it, but it was mentioned as a pro-tip in multiple sessions. You will also notice that informative reference material was added, with more to come as the broader community identifies components that are unclear or missing.
There are several policy changes in the midst of the above updates. While not particularly huge, they are there and worth pointing out. All new CT logs must be temporally sharded. A log that is temporally sharded accepts logging of certificates that fall into a range of expiry dates. For example, a 2020-shard would not accept certificates that expire in 2021. The status of sharding moves from allowed to required, solving the issue of logs that grow forever and ever. A log must additionally not return multiple different SCTs for a single log entry, which solves undefined behavior in RFC 6962 that could lead to unverifiable SCTs in quirky corner cases. Note that a certificate that passes the Google Chrome CT policy is now said to be CT compliant. It is analogous to the current wording of a certificate being CT qualified, and avoids confusion with CT logs that can also be qualified in the browser.
Clint Wilson announced Apple’s intended policy updates. They are also working towards definitions in undefined scenarios, such as expressing their policy in terms of days as opposed to months. The most notable policy update (in my opinion) is that the SCT diversity and quantity assumption for a CT compliant certificate is about to change. Currently, Apple considers a certificate CT compliant if accompanied by two SCTs from any pair of CT logs. Longer-lived certificates will require an additional SCT in the future, and log operator diversity will be added as well. This reduces the risk that a once CT compliant certificate will become non-compliant during its life time. The other benefit is that no single log operator can issue a certificate’s SCTs, which raises the bar towards unnoticed certificate mis-issuance. What it means that two log operators are diverse (also known as independent) is somewhat non-trivial: it can span many different dimensions, such as organization, country, and infrastructural providers. Google’s updated policy for log operators will require a self-assertion that you are independent of all other log operators. My best guess is that Apple will rely on something similar to define log diversity.
Removing the one-Google log requirement?
Google Chrome currently considers a certificate CT compliant if it is accompanied by two SCTs. One of these SCTs must additionally be issued by a log that Google runs. If Google’s CT logs are operated in good faith, we can be sure that there are no mis-issued certificates that go unnoticed.
To state the obvious, the point of CT is not to trust that Google keeps the wider web safe from certificate mis-issuance. The current set-up is in fact quite error-prone: sub-optimal trust assumptions aside, a Google outage would essentially disable issuance of new CT compliant certificates on the web. Devon O’Brien expressed a desire to remove Google from the critical path of certificate issuance, and what considerations that need to go into such a decision. The major part is that Google must accept that they lose their privilege of observing all issued certificates up-front, which provides significant proactive security for Chrome users but might impend broader user-agent adoption. The result of such a change is that SCTs must be audited reactively in the background from many diverse vantage points, such that mis-issued certificates get noticed without the one-Google log policy.
Chris Thompson presented Google’s plans on opt-in SCT auditing. The basic idea is to submit a random subset of SCTs to a Google-operated CT auditor. If an SCT is encountered that Google does not know about, that can be investigated further by challenging the issuing CT logs to prove certificate inclusion. The reason why this requires opt-in stems from the fact that the user is essentially sharing a random subset of its browsing history with Google. You might wonder who would opt-in for that, but it actually fits pretty well into the existing Safe Browsing Extended Reporting (SBER) programme. My largest concern is that opted-in users might be identifiable, and in that case the rest of us could still be attacked without high likelihood of detection.
Sarah Meiklejohn presented a follow-up session on privacy-preserving SCT auditing. It could be described as partial highlights of a systematic literature study that considered 15 different proposals against the following criteria:
- Functionality. Does it work and in what threat model?
- Privacy. What information do which parties learn?
- Client-side performance. Bandwidth, computation, and storage?
- Latency. How much is added, if any?
- Server-side infrastructure costs. What needs to be changed or added?
- Threat model. Mainly in terms of which parties need to trust each other.
- Non-Google deployability. Can it be deployed without Google-scale?
- Near-term deployability. Can we roll it out sooner rather than later?
A subtle message is that a proposal without a third-party CT auditor is incomplete. I share this view because we cannot expect an end-user to take any reasonable action if log misbehavior is suspected. Therefore, it is not just proof fetching that needs to be private: also the process of reporting issues.
Acknowledgments
Thanks to everyone that contributed to CT days 2020, both in terms of organization and putting in the actual work that the different sessions presented. A detailed summary and follow-up discussion might appear on the CT policy list. Fredrik Strömberg provided valuable feedback on this story, which is sponsored by my System Transparency employment at Mullvad VPN.